Spring容器中的bean具备不同的scope,最开始只有singleton和prototype,但是在2.0之后,又引入了三种类型:request、session和global session,不过这三种类型只能在Web应用中使用。
在定义bean的时候,可以通过指定
<bean id="testMock" class="org.test.javadu.TestMock" scope="prototype"/>
或者
<bean id="testMock" class="org.test.javadu.TestMock" singleton="false"/>
1. singleton
配置中的bean定义可以看作是一个模板,容器会根据这个模板来构造对象。bean定义中的scope语义会决定:容器将根据这个模板构造多少对象实例,又该让这个对象实例存活多久。标记为拥有singleton scope的对象定义,在Spring的IoC容器中只存在一个对象实例,所有该对象的引用都共享这个实例。该实例从容器启动,并因为第一次被请求而初始化之后,将一直存活到容器退出,也就是说,它与IoC容器“几乎”拥有相同的“寿命”。
下图是Spring参考文档中给出的singleton的bean的实例化和注入语义示意图,或许更能形象得说明问题。
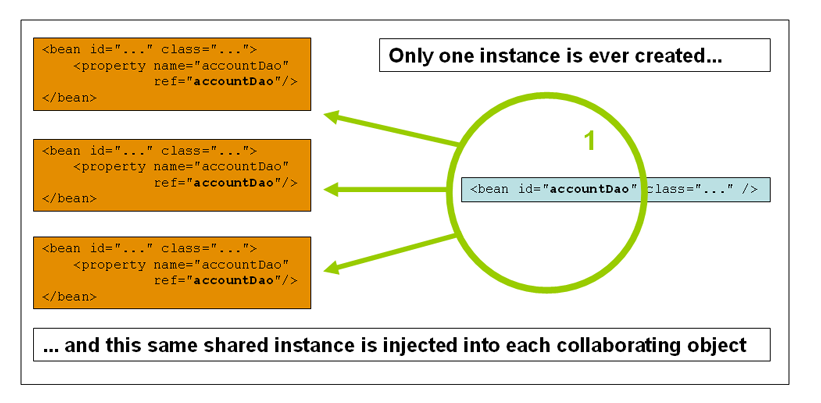
需要注意的是,不要将Spring中的singleton bean的概念和GoF中提出的Singleton模式混淆,二者的语义并不相同:Spring中的singleton scope是指在每个容器中只有一个bean的实例对象;GoF模式中的Singleton指的是在同一个classloader中只有某个Singleton类的一个实例对象。
Spring中的bean默认是singleton的,下面这两种写法的效果相同:
<bean id="accountService" class="com.foo.DefaultAccountService"/>
<!-- the following is equivalent, though redundant (singleton scope is the default) -->
<bean id="accountService" class="com.foo.DefaultAccountService" scope="singleton"/>
2. prototype
针对声明为拥有prototype scope的bean定义,容器在接到该类型对象的请求的时候,会每次都重新生成一个新的实例对象给请求方。虽然这种类型的对象的实例化以及属性设置等工作都是由容器负责的,但是只要准备完毕,并且对象实例返回请求方之后,容器就不再拥有当前返回对象的引用,请求方需要自己负责当前返回对象的后继的声明周期的管理工作,例如该对象的销毁。也就是说,容器每次返回给请求方一个新的实例对象后,就任由这个对象“自生自灭”了。
对于那些请求方不能共享使用的对象类型,应该将其bean定义的scope设置为prototype。这样,每个请求方可以得到自己专有的一个对象实例。通常,声明为prototype的对象都是一些有状态的,比如保存每个顾客信息的对象。
从Spring参考文档下的这幅图片,可以再次了解prototype scope的bean定义,在实例化对象和注入依赖的时候,它的具体语义是什么样子。
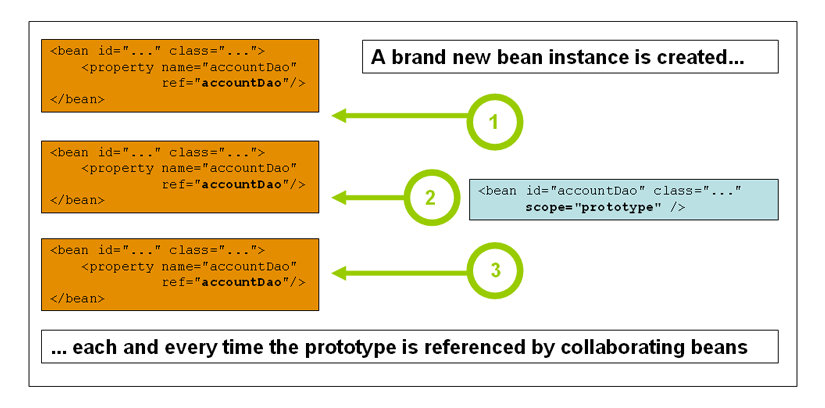
用以下两个ban定义的效果是一样的:
<bean id="accountService" class="com.foo.DefaultAccountService" scope="prototype"/>
<bean id="accountService" class="com.foo.DefaultAccountService" singleton="false"/>
实践教训
今天写这个主题的原因是:在最近的项目中由于对于singleton类型的对象没有理解透彻,导致每日定时任务的统计数据出错。
具体描述如下:每天我需要跑一个定时任务,该任务使用多线程方式去执行,每个线程都需要往一个统一的结果集中写数据,基本的代码结构如下:
public class StatisticsTaskManager {
private static final Logger logger = LoggerFactory.getLogger(OdsManager.class);
private ConcurrentHashMap<Long, StatisticsBean> resultMap = new ConcurrentHashMap<>();
/*对外暴露的统计接口*/
public List<StatisticsBean> getOdsStatisticDataFromUtc() {
ExecutorService pool = Executors.newFixedThreadPool(80);
for (int dbIndex = 0; dbIndex < Constants.DB_NUM; dbIndex++) {
for (int tableIndex = 0; tableIndex < Constants.TABLE_NUM; tableIndex++) {
DealUidRunnable thread = new DealUidRunnable(dbIndex, tableIndex);
pool.execute(thread);
}
}
pool.shutdown();
try {
pool.awaitTermination(6, TimeUnit.HOURS);
} catch (InterruptedException e) {
logger.error("error:", e);
}
logger.info("finished! num={}", resultMap.size());
//resultMap.clear();
return convertMapToList();
}
/*具体的任务执行过程*/
这里会修改resultMap
}
在上述代码片段中,每个线程会判断resultMap中是否有key存在,如果存在则更新对应的bean,如果不存在则新建一个bean。这就要求在每个任务开始执行前,这个resultMap是空的,但是我没有意识到这个resultMap仅仅随着StatisticsTaskManager对象的生成而仅仅初始化一次,后续会作为singleton对象存在于容器中。
修改也非常简单,就是在当天的定时任务执行完之后,调用resultMap.clear()将结果map中的数据清除即可。
参考资料
Spring Boot 1.x系列
- Spring Boot的自动配置、Command-line-Runner
- 了解Spring Boot的自动配置
- Spring Boot的@PropertySource注解在整合Redis中的使用
- Spring Boot项目中如何定制HTTP消息转换器
- Spring Boot整合Mongodb提供Restful接口
本号专注于后端技术、JVM问题排查和优化、Java面试题、个人成长和自我管理等主题,为读者提供一线开发者的工作和成长经验,期待你能在这里有所收获。

13条评论在“Spring中bean的scope”
评论已关闭。